The sentences used in natural language processing problems, such as the sequences of transcription factor proteins we used in our study, are relatively long, and the previous parts should be remembered. In this way, accurate predictions and classifications can be made. Although Recurrent Neural Networks (RNNs) prepared for these situations can remember past information, the desired success cannot always be achieved because they can remember short-term dependencies. In addition, the disappearance of the gradient in backpropagation calculations also reduces the success. Long Short-Term Memory (LSTM) networks designed for these situations aim to increase success by overcoming these problems [1], [2].
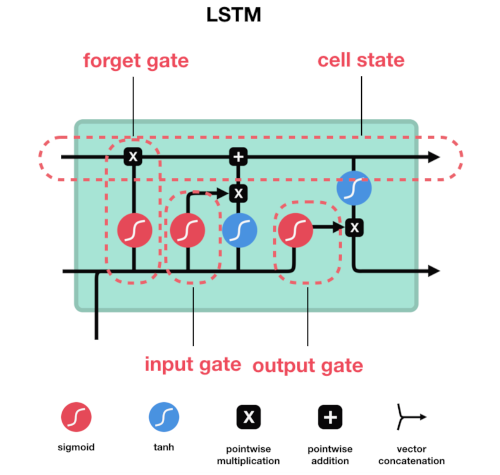
In LSTM networks, there is an input gate, a forget gate, and an output gate. At the entrance gate, it is decided whether to update the previous and current information according to the result of the sigmoid process. Information with 0 is considered unimportant, and information with 1 is considered important. In addition, the tanh activation function, which compresses the data to the range of -1 and 1, is used for the regulation process of the network. Then, the sigmoid and tanh function outputs are multiplied, deciding which information to update. It is the gate that reaches the decision of what information will be forgotten or kept at the forget gate. The information from the previous cell (ht) and the current information (xt) is inserted into the sigmoid activation function, and a decision is made according to the result. Information with 0 is forgotten, and information with 1 is used for updating again at the entrance gate. At the exit gate, the next cell's entrance (ht+1) is determined. It is also used for estimation. The previous information and the information of the current input are passed through the sigmoid function. Then, the information available in the input is passed through the tanh function, and the two results are multiplied to determine the entry of the next cell [1], [2].
The formulation of the LSTM network is given below. Here it is the input gate, ot is the output gate, and ft is the forget gate [3].
it = σ (Wxixt + Whiht−1 + Wcict−1 + bi) (1)
ft = σ (Wxfxt + Whfht−1 + Wcfct−1 + bf ) (2)
ct = ftct−1 + it tanh (Wxcxt + Whcht−1 + bc) (3)
ot = σ (Wxoxt + Whoht−1 + Wcoct + bo) (4)
ht = ot tanh(ct) (5)
References
[1]: S. Hochreiter and J. Schmidhuber, "Long Short-Term Memory," Neural Computation, vol. 9, no. 8, p. 1735-1780, 1997.
[2]: https://medium.com/deep-learning-turkiye/uzun-kisa-vadeli-bellek-lstm-b018c07174a3
[3]: Y. Gao and D. Glowacka, "Deep Gate Recurrent Neural Network," JMLR: Workshop and Conference Proceedings, vol. 63, p. 350-365, 2016.