Members of the bHLH superfamily have two highly conserved and functionally distinct domains, which together make up a region of approximately 60 amino-acid residues. At the amino-terminal end of this region is the basic domain, which binds the transcription factor to DNA at a consensus hexanucleotide sequence known as the E box. Different families of bHLH proteins recognize different E-box consensus sequences. At the carboxy-terminal end of the region is the HLH domain, which facilitates interactions with other protein subunits to form homo- and hetero-dimeric complexes. Many different combinations of dimeric structures are possible, each with different binding affinities between monomers. The heterogeneity in the E-box sequence that is recognized and the dimers formed by different bHLH proteins determines how they control diverse developmental functions through transcriptional regulation. The bHLH motif was first observed by Murre and colleagues in two murine transcription factors known as E12 and E47. With the subsequent identification of many other bHLH proteins, a classification was formulated on the basis of their tissue distributions, DNA-binding specificities and dimerization potential. This classification, which divides the superfamily into six classes, was initially based on a small number of HLH proteins but has since been applied to larger sets of eukaryotic proteins. More recently, an approach using evolutionary relationships was used to classify bHLH proteins into four major groups (A-D), taking into account E-box binding, conservation of residues in the other parts of the motif, and the presence or absence of additional domains. The sequencing of new genomes has led to the identification of additional bHLH families, and this evolutionary classification has now been extended to include two additional groups (E and F; Table 1). Parsimony analysis by Atchley and Fitch of a phylogenetic tree derived from 122 sequences suggested that an ancestral HLH sequence most probably came from group B, and group B proteins are indeed the most prevalent type of bHLH proteins in animals. The situation is similar in the Arabidopisis genome, in which the G-box-binding bHLH proteins (part of group B) are the most abundant group.
| Phylogenetic group | Description | Classification according to Murre et al. | Examples of classified proteins (family names) |
| A | Bind to CAGCTG or CACCTG | I, II | MyoD, Twist, Net |
| B | Bind to CACGTG or CATGTTG | III, IV | Mad, Max, Myc |
| C | Bind to ACGTG or GCGTG. Contain a PAS domain | Single-minded, aryl hydrocarbon receptor nuclear translocator (Arnt), hypoxia-inducible factor (HIF), Clock | |
| D | Lack a basic domain and hence do not bind DNA but form protein-protein dimers that function as antagonists of group A proteins | V | ID |
| E | Bind preferentially to N-box sequences CACGCG or CACGAG. Contain an orange domain and a WRPW peptide | VI | Hairy |
| F | Contain an additional COE domain, involved in dimerization and DNA binding | Coe (Col/Olf-1/EBF) |
One basis for the evolutionary classification shown in Table 1 is the presence or absence of additional domains, of which the most common are the PAS, orange and leucine-zipper domains. PAS domains, located carboxy-terminal to the bHLH region, are 260-310 residues long and function as dimerization motifs. They allow binding with other PAS proteins, non-PAS proteins, and small molecules such as dioxin. The PAS domain is named after three proteins containing it: Drosophila Period (Per), the human aryl hydrocarbon receptor nuclear translocator (Arnt) and Drosophila Single-minded (Sim). The domain is itself made up of two repeats of approximately 50 amino-acid residues (known as PAS A and PAS B) separated by about 150 residues that are poorly conserved. PAS-domain-containing bHLH proteins (bHLH-PAS proteins) form phylogenetic group C. A distinct additional domain, the orange domain, is a 30-residue sequence that is also located carboxy-terminal to the bHLH region, from which it is separated by a short, variable length of sequence. Transcription factors with this additional domain, designated bHLH-O and forming part of phylogenetic group E, include the hairy-related proteins, called HEY1, HEY2 and HEYL in mouse and humans. The molecular function of the orange domain is still unclear; it has been proposed that it mediates specificity and transcriptional repression, but there is also evidence that it can play a role in dimerization.
A number of bHLH protein families, mostly in phylogenetic group B, have a leucine-zipper domain contiguous with the second helix of the HLH domain; like the HLH domain, this mediates dimerization. Proteins that have only a leucine-zipper domain coupled with a basic domain (denoted bZIP) and no HLH domain are a separate family of DNA-binding proteins in their own right. The sequence of the zipper consists of a repeating heptad, with hydrophobic and apolar residues occurring at the first and fourth positions and polar and charged residues at the remaining positions. Leucine is the residue that predominates at position 4; it thus lends its name to the zipper motif. One bHLH protein that has a leucine-zipper domain (and that is therefore denoted a bHLHZ protein) is Max, which forms the hub of a network of bHLH transcription factors. Max is known to form homodimers and heterodimers with the group B proteins Myc, Mad, Mnt and Mga, and these complexes each have sequence-specific DNA-binding and transcriptional functions.
The additional domains in bHLH proteins, such as the leucine zipper, are always carboxy-terminal to the bHLH region. The position of the bHLH and additional domains within the complete sequence of the protein varies widely between different families, however. This variable pattern of domain positioning has led to the proposal that bHLH proteins have undergone modular evolution by domain shuffling, a process that involves domain insertion and rearrangement.
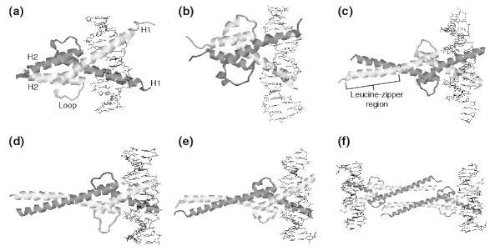
The figure representatives structures of bHLH proteins from the Protein Data Bank. In each diagram, the protein is shown as a secondary-structure cartoon and the DNA double helix is shown in stick representation. (a) MyoD bHLH-domain homodimer (PDB code 1mdy). (b) Pho4 bHLH-domain homodimer (1am9). (c) SREBP-1a bHLH-domain homodimer (1aoaC). (d) Max-Mad heterodimer (1nlw). (e) Max-Myc heterodimer (1nkp). (f) Max-Myc heterotetramer (1nkp). In (d-f) the Max HLH monomer is shown in dark gray. The scales are not comparable between different structures.
The following table shows the bHLH protein structures in the Protein Data Bank (PDB).
| PDB code | Protein Chains | Protein name | Species | Group | SCOP superfamily | CATH homologous superfamily | CATH sequence family |
| 1mdy* | ABCD | MyoD bHLH | Mouse | A | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.1 |
| 1an4 | AB | USF bHLH | Human | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.2 |
| 1an2 | AC | Max bHLHZ | Mouse | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.2 |
| 1hlo | AB | Max bHLHZ | Human | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.2 |
| 1nlw* | BE | Max bHLHZ | Human | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.2 |
| 1nkp* | BE | Max bHLHZ | Human | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.2 |
| 1nkp* | AD | Myc prot-oncogene bHLHZ | Human | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.2 |
| 1am9* | ABCD | SREBP-1a bHLHZ | Human | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.3 |
| 1ukl | CDEF | SREBP-2 HLHZ | Human | B | NC | NC | NC |
| 1a0a* | AB | Pho4 bHLH | S. cerevisiae | B | Helix-loop-helix DNA-binding domain | MyoD basic-helix-loop-helix domain, subunit B | 4.10.280.10.4 |
| 1nlw* | AD | Mad bHLHZ | Human | B | Helix-loop-helix DNA-binding domain | NC | NC |
References
[1]: S. Jones, "An overview of the basic helix-loop-helix proteins," Genome Biol., vol. 5, no. 6, p. 226, 2004.